
Really trying to understand and explain REST in detail.
The term REST pops up again and again in web programming. Usually in contexts like "our API is RESTful." But no one claims "our API is RESTless." So like a lot of things when learning to program (avoiding global variables, separating presentation from content, etc.), the beginner is told time and again how important, how vital it is to act a certain way. Without really understanding exactly how to act or why it's important.
Some mentors try to pass off this shallow understanding with a Charge of the Light Bridgade sort of quip.
Theirs not to make reply, Theirs not to reason why, Theirs but to do and die. Into the valley of Death Rode the six hundred.
Yes, there are times to simply bypass the brain, accept an imperfect understanding, and glory in pure action.
Seeking to understand the abstract principles behind robust computer architecture? This isn't one of those times.
In the same spirit as What is the DOM?, I want to try to explain REST in a clear, simple way.
So to understand REST, where does aspiring web programmer begin? Usually Wikipedia. Going to the Wikipedia REST article is more intimidating than helpful for the novice. But with a little additional background, that REST Wikipedia article can be very helpful. Much of the rest of this post will be a gloss on the Wikipedia article.
Another good resource for learning about REST is the blog post How I Explained Rest to My Wife. (A friend of mine forwarded it to me a few days ago. It is the proximate cause of this blog post.)
To begin, Wikipedia says REST is the "predominant web API design model." I wrote another post on APIs trying to get at what exactly APIs are and why they are important. Go read that first if you feel fuzzy on what exactly APIs are.
The "predominant web API design model" is used by the predominant web API: HTTP.
HTTP powers the Internet. The first part of a website address says, "Hey, this website uses HTTP."
HTTP was the first interface to implement REST on a large scale. Or maybe REST was a byproduct that came out of HTTP's development. Something like that. Whatever. The point is this: REST and HTTP go together like peanut butter and jelly.
The advantages of HTTP are manifold. Most importantly, HTTP makes things simpler.
HTTP is the interface layer between different clients and servers. Whenever I type a URL into the address bar of a browser and hit enter, that issues an HTTP GET request to the server at the URL.
The server could be a Ruby on Rails server. Or a PHP server. Or an ASP .NET server. Or any of a hundred other types of servers.
The client could be Chrome. Or Firefox. Or a screen reader for a blind person. Or it could be some sort of automated program. Like a script using cURL.
The clients and servers just have to agree to all speak the same language. They all can listen to HTTP and respond with HTTP.
REST is the name for an application that:
maximizes the use of the existing, well-defined interface and other built-in capabilities provided by the chosen network protocol, and minimizes the addition of new application-specific features on top of it.
This is written in an abstract way, so it could apply to any number of chosen network protocols. But, for now, 95% of the time when we talk about a RESTful network protocol, we are talking about HTTP.
So to rewrite the above in a less abstract way:
RESTful code maximizes the use of the existing, well-defined HTTP interface and other built-in capabilities provided by HTTP, and minimizes the addition of new application-specific features on top of HTTP."

Every HTTP request has a request method. There are four main request methods in HTTP:
At the most basic level, a RESTful API uses these HTTP request methods, rather than reinventing the wheel.
So how to use these request methods? An example is the easiest way to explain them:
Suppose you "store your credit cards for future use" at an online store. The online store keeps a list of credit credits you've used, so the next time you log in, you don't have to retype the card information.
Now suppose you are buying something. You want to get a list of these stored credit cards back from the server. Let's say you are user #123. Since you want to GET data from the server, you use the GET HTTP method:
GET /user/123/card
The first part is the request method. It tells the server what you want. You want to GET data. The second part is the resource identifier. It identifies what you are interested in. You are interested in the credit cards of user 123.
The full resource identifier you'd see in your browser is http://www.onlinestore.com/user/123/card has two parts:
The first part identifies which specific server you want to send the request to. The second part identifies where on the server you want to send the request.
The server doesn't need to worry about part 1. It knows who it is. So within the server, the GET request just shows up as:
GET /user/123/card
Now let's say you just want to GET data about a specific card. Say the fifth card you used.
GET /user/123/card/5
Again, the request method tells the server you want to GET data. The second part identifies what you want data about. Specifically, the fifth credit card of user 123.
Now let's say you just moved into a swanky new apartment. So you need to update the billing address for credit card 5. You fill out your new address into a form and hit submit. Which sends an HTTP request. But not with the HTTP GET request method:
POST /user/123/card/5
The POST method tells the server you don't want to GET data from the server. You want to add data to the server. In this case, you want to update the server data for the fifth credit card of user 123.
Notice the second part of the POST request, the resource identifier, is exactly the same as in the previous GET request: /user/123/card/5. You are talking about the same card as before. You are just requesting the server do something different to the card (GET server data vs POST new data to the server).
Now, let's say you want to use a new credit card. You fill out a form and hit submit. Which sends this request:
PUT /user/123/card/6
The server receives the request and knows, "Oh. The client wants to put a new card on the server."
Lastly, let's say you cancel a card and need to delete it from the server. You select the card then click the submit button, which sends this request:
DELETE /user/123/card/2
HTTP is just a protocol. It's just a language both the client and the server understand. You can use this language any way you want. You can use the language in ways that aren't RESTful.
For example, you can send all your requests as HTTP GET requests. And then indicate somewhere else within the request whether or not you want to get data from the server, post new data to the server, or delete data from the server. But why reinvent the wheel? Why not just use tell the server this in the conventional way, with the request method?
Other people will be able to understand your code. You will be able to understand other people's code.

So perhaps you are saying: "So is that all there is to REST? That's simple enough. Seems like much ado about nothing."
But not so fast, my dear Claudio. We are not quite done yet. That is just the beginning of REST. Using request methods is just the most basic way in which an API is RESTful.
Wikipedia goes on to list the six key constraints of REST. I'm sure the constraints is the technically accurate term. But we are just trying to grok REST at the moment, not trying to understand all the technicalities. Let's call these the six principles of REST for now.
So what separates RESTful code from non-RESTful code? RESTful code has the six principles, non-RESTful does not. Here are the principles:
If you learn what those six things mean, you'll know what REST is! And you'll have gone a long way toward understanding why it is important.
1) Client-server
The first principle of REST is the client-server model. The Internet runs on the client-server model. The Internet is just a really large computer network filled with clients and servers. You are reading this page on a client (your laptop, smartphone, whatever). The page was sent to you by a server.
The most basic way to think of a network is to imagine two--just two--computers communicating with each other. The network is the means by which these two computers communicate. The most simple network consists of a wire connecting two computers, and the software that enables the computers to understand each other.
REST is a way to write that software. It is a style in which to build the software. It is a style of software architecture. It's not so much the Victorian manor-house style of architecture, with a grand ballroom and servants' quarters. REST is more like a bunch of independent four-story buildings filled with little individual offices and apartments.
Not all computer networks have to follow the client-server model. In fact, up until 1990 or so, most networks actually didn't follow the client-server model. They used the mainframe model. In that model the computer you use (the display, the keyboard, etc.) is incredibly dumb. This dumb computer is called a "thin client" or "terminal." Basically, all the thin client can do is transmit to the mainframe and then display the results the mainframe sends back. The mainframe does all the work.
In the client-server model, the client (your PC) is no longer dumb. It's pretty smart. It's a thick client. It can do some of the work.
Why is this important? Well, before remember the mainframe was trying to handle everything. If the mainframe fails, then everything stops. With the client-server model, the client is smart. It can figure out what to do if the server screws up.
Whenever you type in a URL for a major website--say www.gmail.com--your computer doesn't just receive a single server to get the data from. It receives a list of servers. If it cannot receive data from the first server, it tries the second server. If that server doesn't work, it moves on to the next one. And so on. Automatically. Invisibly.
Servers are failing all the time. Whenever you are surfing the Internet, your computer is recovering from errors on websites all the time. The client-server model makes this possible.
Client-server style software is robust. A lot of independent parts can fail. Yet the system as a whole can go right on working.
This robustness is one advantage of the client and server being separate, independent agents that can think and act for themselves.
Another advantage is efficiency. The client doesn't have to tell the server everything it is doing. And vice versa. The server doesn't worry about what the client will do with the data. The server just worries about providing the data the client needs. The client doesn't worry about how the server gets the data. The client just patiently waits until the server delivers what it needs. This is called separation of concerns.
2) Stateless
Water can be in three states: liquid, solid, or gas. No matter what state it is in, it is still water. State is some specific characteristic that some specific group of water has. The state of the water in the glass on my desk is liquid. The state of the ice cubes in my freezer is solid. The state of the steam rising from my rice cooker is gas.

The more you read in programming, the more you read about "state." Specifically, you read about ways to avoid keeping track of state. Writing code that is stateless.
One REST principle is that the server does not keep track of the state of the clients that request data from it.
For example, Alice wants some pictures. Preferably in the JPG format. She sends in a request to the server from her client, and somewhere in that request, she indicates the that she wants the pictures in .JPG format.
Bob also wants pictures. But he wants them in the .PNG format. So he indicates that in his request.
The opposite of the stateless server is the stateful server. The stateful server would try to keep track of "Oh ok, Bob wants PNG and Alice wants JPG." So in future requests, Alice and Bob could leave out their preference for image format. The server already knows. This makes requests to the stateful server shorter, and thus faster and more efficient.
A lot can go wrong with stateful servers. For one, suppose the initial request is delayed, where Alice indicates which picture format she wants. Then Alice's client sends a second request but leaves out a picture format preference, thinking the server already knows. But the server doesn't know yet. So it sends back the wrong format.
Now, with a stateless server, the client keeps track of which picture format it wants. It automatically sends that data along with every request. So it doesn't matter which request arrives at the server first. Both will be processed correctly.
Another thing that can go wrong with stateful servers is that they might get confused about which client they are talking to. Let's say that Alice requests 10 images on Monday from home. The next day she takes her laptop to a coffeeshop. She requests another 10 images. The client thinks the server already knows which image format she prefers, so the client doesn't send the data. But the server doesn't recognize the client. So it sends back the images in the wrong format.
Stateless servers help with the separation of concerns we talked about earlier. The client knows who it is and what it wants. The server doesn't need to keep track. The server just sees "request for PNG image" and "request for JPG image" and spits back the image in the right format.
3) Cacheable
Clients can cache responses from servers. So let's say Alice requests the file ice-cubes.jpg in her web browser (her client). The server responds with the image, and that file is stored in her web browser's cache.
Then ten minutes later, Alice requests to look at the same picture again. But before every request, her client checks its cache to see if it already has what Alice is requesting. In this case, it already has the picture of ice-cubes.jpg that it fetched 10 minutes ago. So it doesn't send the request to the server at all. The client just loads the image instantly for Alice.
Images, video, music, HTML, CSS, and Javascript are all cacheable as well. This is the main reason why it usually takes longer to load a website the first time you visit. On the second visit, much of the website is already cached on your computer. The server doesn't need to send it again.
One of the reasons why caches work well in REST is that that separation of concerns between the client and the server. The server doesn't care whether the client requests all the images for the first time or just one new image that isn't in already in its cache. All the server sees is a series of requests that say "the client wants this image" and "the client wants this HTMl document" and so on.
4) Layered system
REST archictecture is layered. There's a client, then there's the first layer of servers, then the second layer of servers, then the third, and so on.
So Alice's client requests an image from some server named blue-server. Now blue-server might not have the image. But blue-server knows who does have the image: red-server. So blue-server requests the image from red-server and receives it. Then blue-server sends the image back to Alice to complete the request.
Now here's the key: the layers are separated. Alice's client had no idea that blue-server didn't have the image and had had to fetch it from red-server. This is another part of separation of concerns. The client doesn't care how the server fetches the requested data. It's the server's job to worry about that. All the client knows is it issued a request for some data, and the server sent back a response with the data.
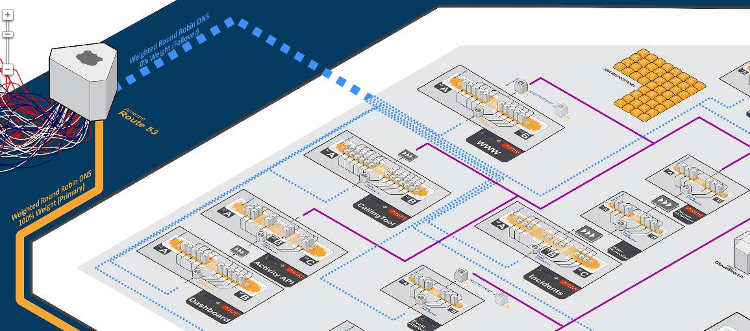
Now for any reasonably large website, there isn't just the client layer, server layer 1, and server layer 2. There are dozens or hundreds of layers.
Here's part of a diagram for a large website that got rather a lot of traffic in November 2012:
5) Code on demand
In addition to sending text and images and such, the server can also send executable code.
This principle is optional.
6) Uniform interface
The style in which clients and servers exchange messages and interact with data on the server (resources) is uniform.
We've already seen one way in which the interface is uniform: HTTP request methods.
But REST's uniform interface goes beyond just request methods. RESTful interfaces share four key characteristics:
Identification of resources:
Resources are identified by our old friend, the resource identifier: /user/123/card/5
On a server, we have a bunch of webpages, images, songs, etc. Each of these is a resource. The conventional (i.e., uniform) way to identify these resources is with the URI or Uniform Resource Identifier. You are probably more used to the more common URL or Uniform Resource Locator. Don't worry about the difference. Every URL is a URI.
If you type the URL http://highwaterlabs.com/img/yoda.jpg into your browser, you get a yoda picture back. The URL identifies which resource you want the server to send back.
Now there are any number of ways to identify which resources you want the server to send back that don't involve the URL. For example, I could use the request method to identify the resource and the resource identifier to specify the request method. So my request would look like:
/user/123/card/5 GET
Assuming the server was configured to interpret requests backward like this, this would totally work. But no one else could visit the website. Their browser would send GET as the request method, like normal.
The more common way that websites violate the "Uniform Identification of Resources" of REST isn't by putting the resource identifier where the request method should go. It's by stuffing the resource identifier somewhere else within the HTTP request. And having the server process this non-uniform resource identifier.
These websites and APIs might work. But they aren't RESTful.
A RESTful API uses URLs to identify resources. To identify credit card 5 of user 123, it uses:
/user/123/card/5
Why reinvent the wheel? We already have a conventional, uniform way to identify resources, that 99% of websites use. Your website or API should use URLs too.

Manipulation of resources:
The picture sent back to the client by the server (the representation) and the picture on the server (the resource) are two different things. The picture sent back to the client is a copy of the picture on the server. You can manipulate the picture on your computer (representation) all you want, but it won't change the picture on the server (resource).
What is more, the representation sent to the client might be different than the resource on the server. The copy might be altered somehow. For example, if the client is a cell phone, the server might shrink the image resource and send back a smaller representation that loads more quickly.
This principle specifies something that every representation should have:
If the client is permitted to modify or delete the resource, the representation should provide enough background info so that the client can do so. The client shouldn't need to go searching for additional background info about the resource so that it can modify it.
Self-descriptive messages:
Each message contains enough information that it is independent, it can "make sense on its own."
Hypermedia as the engine of application state (HATEOAS):
This is a long name for a simple concept: you start at some entry point, and from that entry point, you can discover new parts of a webpage. The simplest way this happens is through hyperlinks. You don't need to remember the different urls for all the different sections of this site. There are links all along the top and bottom of the site you can use to explore.
Throughout the site, there is a web of hyperlinks you can navigate. You don't need to remember the urls of specific blog posts. You can click blog then click on the link for the post you want.
For more on how this applies to web applications, check out Haters Gonna HATEOS.
So that's it. Now you know what REST is. RESTful code uses HTTP request methods. RESTful code uses URLs. And RESTful code has separation of concerns between the client and server.
RESTful code follows all six principles:

{kind=link}